Resumo AOC - P2
Conteúdos
- Casos para a multiplicação
- Casos para a multiplicação
- Casos para a multiplicação
- Casos para a multiplicação
- Resumo AOC - P2
- Tabela de conversão decimal - hexadecimal
- Tabela de conversão decimal - hexadecimal
- Tabela de conversão decimal - hexadecimal
- Tabela de conversão decimal - hexadecimal
- Tabela de conversão decimal - hexadecimal
- Tabela de conversão decimal - hexadecimal
P1) Um dos objetivos que orientam o projeto de um sistema de memória é alcançar capacidade de armazenagem, com desempenho aceitável a um custo razoável. Como este objetivo pode ser alcançado? Faça um esboço desta estrutura?
Esse objetivo pode ser alcançado usando camadas de memória, por exemplo, a memória Cache. Uma memória menor, porém, construída perto do processador, diminuindo o número de visitas a memória RAM.
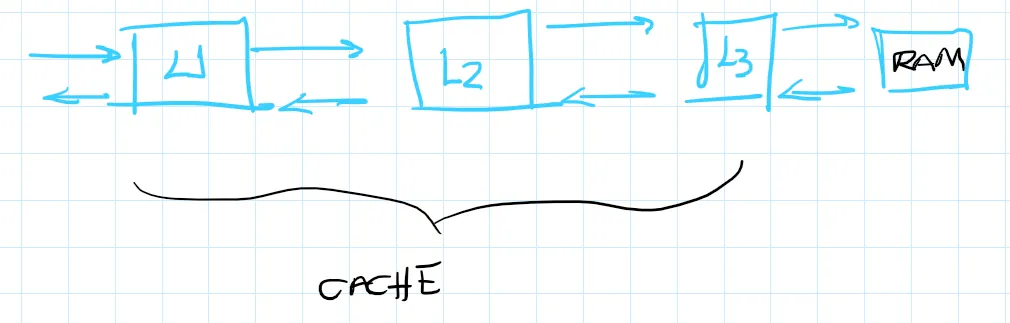
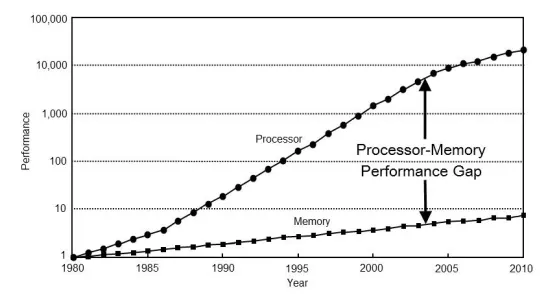
P2) O acesso à memória é um enorme gargalo em todos os computadores modernos porque o tempo de ciclo da CPU é muito superior ao tempo de acesso à memória. A Figura1 mostra a performance da memória e da CPU no período 1980-2010. Dessa forma, uma das maneiras de melhorar o desempenho de computadores atuais é evitar acessar à memória principal. O tempo de acesso à memória principal é alto e degrada o desempenho do sistema computacional. A estratégia de usar memória cache tenta suprir essa lacuna existente no desempenho relativo CPU/Memória e assim o uso de memória cache tornou-se um dos principais temas a ser analisado no projeto de um sistema computacional.
Considerando tais informações e seus conhecimentos a respeito do projeto de memória cache, responda as questões a seguir:

a)
b) O cache L2 apresenta um tamanho maior por motivos de ser um reserva para, caso um possível miss no L1, tal informação possa estar contida no L2 de modo a não necessitar o acesso a Main Memory
P3) Qual é o significado dos termos byte-endereçável ou palavra-endereçável?
O termo byte-endereçável significa que cada Byte(palavra) contém um endereço próprio exclusivo para ser acessada
P4) O que significam princípio da localidade da referência e princípio da inclusão em organização hierárquica de memória?
O princípio da localidade de referência significa que o dado usado mais recentemente tem maior probabilidade de ser acessado novamente no futuro
P5) Uma medida dos benefícios de diferentes organizações de cache é a taxa de falta (miss rate). Onde taxa de falta é a fração de acessos a cache que resultam em faltas. Denomine e descreva quais são as três categorias associadas as causas de falta de cache (miss cache):
Falhas associadas à falta de cache (miss cache) podem ser classificadas em três tipos:
- Compulsórias: o primeiro acesso a um bloco não pode ter sucesso (falhas de arranque frio)
- Capacidade: falhas causadas pela ausência de blocos que já estiveram em cache mas foram retirados por falta de espaço.
- Conflito: são falhas causadas pela impossibilidade de ocupação simultânea de uma posição ou conjunto (falhas de colisão ou interferência).
P6) Um sistema de cache tem uma taxa de acerto de 75%, um tempo de acesso de 10ns quando o dado for encontrado no cache e um tempo de acesso de 100ns se o cache não contiver o dado. Qual é o tempo de acesso efetivo?
TempoMedio = Hit-Time + (1 – Hit-Rate)**Miss-Penalty TM = 10ns + (1-(75/100))100 TM = 10ns + (0,25)*100ns = 10ns + 25ns = 35ns
P7) Por que é tão difícil construir um cache full associative?
Como a característica do mapeamento total associativo é cada bloco entra em qualquer linha, para encontrar algum dado no cache é necessário verificar todas as linhas do cache a fim de encontrar a tag específica, tornando altíssima a complexidade do circuito necessário para comparar as tags de todas as linhas da cache em paralelo
P8) Para esta tarefa, você deve assumir que a memória principal consiste em 128 palavras (words) dividida em blocos de 4 palavras cada (32 blocos). A memória cache consiste em 8 linhas cache (slots).

a)
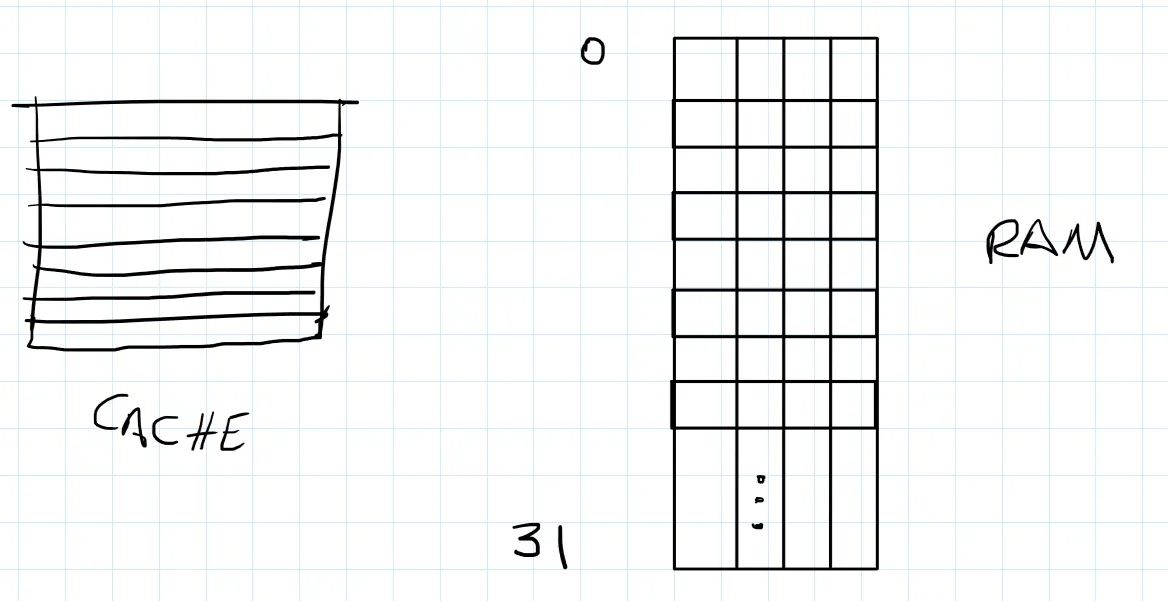
b)i)
Set 0 – 0,8,16,24
Set 1 – 1,9,17,25
Set 2 – 2,10,18,26
Set 3 – 3,11,19,27
Set 4 – 4,12,20,28
Set 5 – 5,13,21,29
Set 6 – 6,14,22,30
Set 7 – 7,15,23,31
ii)
A arquitetura tem que ter no mínimo 7 bits, sendo eles distribuídos da seguinte maneira:
Como são 8 linhas da cache, logo são necessários 3 bits para o SET
Como cada bloco é formado por 4 palavras, logo são necessários 2 bits para o OFF
Sendo assim sobrando 2 bits para a TAG
iii)
4 – 0000100 – Tag = 00, Set = 001, Off = 00
13 – 0001101 – Tag = 00, Set = 011, Off = 01
39 – 0100111 – Tag = 01, Set = 001, Off = 11
89 – 1011001 – Tag = 10, Set = 110, Off = 01
8)c)i) Não é possível fazer essa listagem, pois no mapeamento associativo cada bloco vai de forma aleatória para uma linha do cache
ii)
Como temos 128 palavras distribuídas em blocos com 4 palavras, logo:
Tag = 5bits
Word = 3 bits
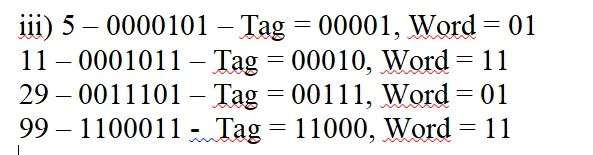
P9) Escreva a fórmula do tempo médio de acesso a memória (Average Memory Access Time - AMAT) quando há dois níveis de cache L1 e L2.
![]()
![]()
P10) Por que um cache de segundo ou terceiro nível é útil? Que tipo de benefícios proporciona ao desempenho do sistema?

Os multi níveis de cache são úteis por que aumentam o desempenho, evitando que a main memory seja acessada, caso ocorra um miss no nível L1, por terem um maior armazenamento
a) Os multi níveis de cache são úteis por que aumentam o desempenho, evitando que a main memory seja acessada, caso ocorra um miss no nível L1, por terem um maior armazenamento
b) Utilizar mais níveis de cache altera o cálculo no sentido de adicionar AMATL2 e o AMATL3 , aumentando o tempo de médio de acesso à memória
c) Técnicas como, mapeamentos mais inteligentes como, Associativo por blocos e utilizar políticas de escrita na hora de substituir os blocos
P11) Vamos considerar um computador com um cache L1 e uma hierarquia de memória cache L2. Suponha que em 1000 referências de memória haja 80 erros em L1 e 40 em L2.

a) MissRatioL1 = 80/1000 MissRatioL2 = 40/1000, MissRatioL2 = 40/80
b)AMAT = HitTimeL1 + MissRatioL1(HitTimeL2 + MissRatioL2MissPenaltyL2)
AMAT = 1 + 8%*(20 + 50%*200) = 10.6 ciclos de clock
P12) O tempo médio (esperado) para acessar a memória (AMAT - Average Memory Access Time), pode ser calculado pela seguinte formula:

0,551 + 0,31511+0,03561 + 0,1161= 22,25
0,8*3+
P13) Um cache está sendo projetado para um computador com 232 bytes de memória. O cache terá 2K slots e usará um bloco de 32 bytes. Calcule, tanto para um cache associativo quanto para um cache com mapeamento direto, quantos bytes o cache precisará ter capacidade de armazenar.
Para o mapeamento direto, temos:
Set – 11Bits
Word – 5Bits
Tag – 16 Bits
Um total de 32 Bits
Já para a associativo, temos:
Tag – 27 Bits
Word – 5Bits
Totalizando 32Bits também. Como o cache tem 2K Slots, e ambas os mapeamentos têm o mesmo tamanho, logo o cache precisará armazenar 64KBits, totalizando 8KBytes
P14) Escreva uma expressão que compute o endereço em memória, a partir de um endereço inicial dado V=&V[0][0], de qualquer elemento de uma matriz com N ×M elementos do tipo inteiro.
A[i][j] = ((i * Ncol) + j) * element_size)
P15) Projete e desenhe um diagrama detalhado de uma memória cache com capacidade de 1 Mbytes, mapeamento direto (associatividade unária), 8 palavras por bloco e escrita preguiçosa. O processador emite endereços de 32 bits.

a) Tag - 15 bits | Set - 14 bits | Off - 3 bits
b) Tag - 15 bits | Set - 14 bits | Off - 3 bits. LRU.
P16) O processador Intel 80486 tem um cache unificado, interno ao chip. Ele contém 8 kbytes e é estruturado como 4-way set associativo. O tamanho das linhas cache é para palavras de 32-bits. Mostre como os bits de um endereço de 32-bits seriam interpretados para este cache (tag, set, byte fields).
Como cada linha da cache é para palavras de 32 bits e a cache tem uma capacidade de 8KBytes resultando em 28 linhas
Como a cache tem uma arquitetura 4-way set associativo, logo a cache é dividida em Sets de 4 linhas, sendo então 26 Sets logo:
Set – 6Bits
Word – 2Bits
Tag – 20Bits
P17) Apresente quais técnicas poderíamos empregar no projeto de organizações hierárquicas de memória para reduzir a penalidade de uma falta (miss penalty)?
Early restart, Critical Word First e multi-níveis de cache.
P18) Considere o programa de multiplicação de matrizes abaixo. As matrizes contêm 1024x1024 elementos, cada elemento um double (8 bytes). O programa é executado num único processador, num sistema de memória virtual com páginas de 4 Kbytes. Existe uma cache primária com 64 Kbytes e uma cache secundária com 1 Mbytes. Os blocos de cache primária tem 32 bytes de largura, e os blocos da cache secundária 64 bytes. Descreva o comportamento da hierarquia de caches durante a execução deste programa.
a) A ideia por trás da localidade espacial é que se um programa acessou dados em um endereço X, é provável que acesse outros itens próximos a X também. Dessa forma, nesse código, o programa, ao acessar os dados próximos do endereço inicial explicita uma localidade espacial.
b) A ideia por trás da localidade temporal é que ao acessar uma informação, é provável que ela seja acessada novamente num futuro próximo. Dessa forma, nesse código, o programa, ao acessar os mesmos dados durante as iterações, explicita uma localidade espacial.
P19) Considere duas organizações de memória cache. A primeira é estruturada como um cache de 32 KB, 2-way set associative, blocos de 32-bytes. A segunda organização é estruturada como um cache de 32 KB , mapeamento direto, blocos de 32-bytes. O tamanho do endereço de ambas é de 32 bits. Considere que um multiplexador 2/1 tenha uma latência de 0.6ns, enquanto um comparador de kbits tem uma latência de k/10ns. A latência de um cache hit (acerto) na organização associativa por conjuntos é definida por H1, enquanto a latência do cache hit da organização com mapeamento direto é definida por H2. Determine o valor de H1.
Sabendo que:
L1 – Largura = 32Bytes – Armazena 4 palavras por vez
L2 – Largura = 64 Bytes – Armazena 8 palavras por linha
Primeiro vamos analisar oque ocorre com as solicitações para a matriz “a”
Como o programa acessa a matriz “a” por linha, então quando o processador faz a requisição para a[0][0] ocorre um cache miss, em L1 então é requerido a L2 tal informação, gerando também um miss no mesmo, então a memória principal é acessada e por localidade espacial, são carregados os dados a[0][0] até a[0][7] para L2, porém é passado para L1 os dados de a[0][0] até a[0][3], devido a sua capacidade reduzida de apenas 4 palavras, então para as requisições a[0][1], a[0][2], a[0][3] ocorrerá um cache hit, pois essas informações já foram previamente carregadas, porém quando for requerido a[0][4] ocorrera um cache miss em L1 e então a solicitação será passada para L2, onde ocorrera um cache hit, e, também por localidade espacial, serão passados os dados de a[0][4] até a[0][7], logo:
L1 – Miss Ratio = 25%
L2 – Miss Ratio = 12,5%
Primeiro vamos analisar oque ocorre com as solicitações para a matriz “b”
Então quando o processador faz a requisição para b[0][0] ocorre um cache miss, em L1 então é requerido a L2 tal informação, gerando também um miss no mesmo, então a memória principal é acessada e por localidade espacial, são carregados os dados b[0][0] até b[0][7] para L2, porém é passado para L1 os dados de b[0][0] até b[0][3], devido a sua capacidade reduzida de apenas 4 palavras, porém como o programa acessa a matriz “b” por coluna, o próximo requerimento será b[1][0], gerando novamente um cache miss tanto em L1 quanto em L2, logo:
L1 – Miss Ratio = 100%
L2 – Miss Ratio = 100%
Sendo tais resultados negativos não devido a erros do cache, e sim pela forma que o programa foi arquitetado
P20) Considere o fragmento de código a seguir, armazenado na memória a partir do endereço 0x1000100C. Todas as instruções na máquina alvo possuem 4 bytes de tamanho:
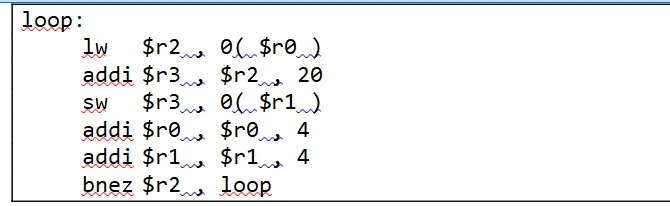
Como o cache tem um armazenamento de 32KBytes, com cada linha comportando 32Bytes, logo o cache tem 1K linha, como tem arquitetura 2-way set associative cada set tem 2 linhas, logo temos 29 Sets, então:
Set – 9Bits
Word – 5Bits
Tag – 18Bits
Como o comparador kbits compara as tags, logo a latência é de:
Latencia = 0,6ns + 18/10ns = 0,6 + 1,8 = 2,4ns
P21)

P22)

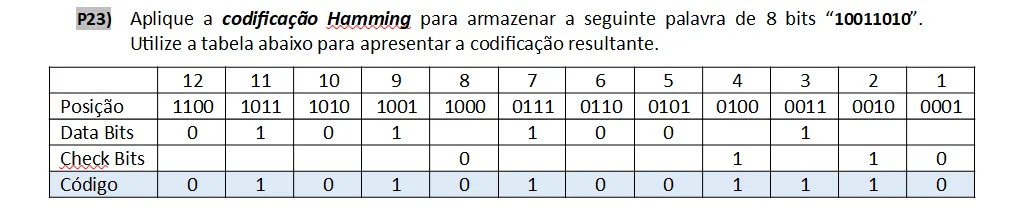
P23)