
Trabalho 1 - 07 03
Conteúdos
- Trabalho 1 - 07 03
- Trabalho 2 - 15 03
- Trabalho 3 - 21 03
- Trabalho 4 - 29 03 Nome: Lucas Lima do Nascimento
Matrícula: 11721EMT014
1. Discuta as vantagens de um SBD quando comparado com um sistema de arquivos.
Um sistema de banco de dados possui algumas vantagens em relação à um sistema de arquivos tradicional, são elas:
- Independência dos dados: O sistema de banco de dados provê uma visão abstrata aos dados, ocultando informações sobre os detalhes de armazenamento
- Acesso eficiente aos dados: O sistema de banco de dados várias técnicas eficientes relacionadas a armazenamento e recuperação de dados
- Integridade e segurança dos dados: O sistema de banco de dados pode forçar restrições de integridade, além de poder fazer controle de acesso aos dados baseado no usuário que está acessando.
- Administração de dados: Centralizar a administração dos dados pode fornecer significativas melhorias em relação ao funcionamento do banco de dados, reduzindo a redundância e realizando sintonizações eficientes.
- Acesso concorrente e recuperação de falha: Um SBD planeja o acesso concorrente aos dados, além de proteger os usuários de falhas no sistema.
- Tempo reduzido de desenvolvimento: O SBD suporta várias funções recorrentes a vários aplicativos, agilizando o desenvolvimento em relação ao acesso dos dados.
2. Analisando a estrutura de componentes do SGBD dada em aula, explique o que ocorre em cada componente e como é o fluxo de dados/informações entre os componentes.
O fluxo começa com a solicitação de um usuário (seja ele experiente, através de comandos SQL, ou inexperiente, através de uma interface, formulário, etc.) para uma consulta no SGBD.
Assim que o usuário emite a consulta, ela é apresentada a um otimizador de consulta (ou processador de consultas) que usa as informações sobre armazenamentos disponíveis para traçar um plano de execução eficiente e depois é levada para um executor do plano.
Esse plano, em linhas gerais, é normalmente representado como uma árvore de operadores relacionais e o código que implementa esses operadores encontra-se acima da camada de arquivos e métodos de acesso. Lá se encontram coleções de páginas ou coleções de registros que tem como finalidade controlar as páginas de um arquivo e organizar as informações dentro da página.
O código da camada de arquivos e métodos de acesso está acima do gerenciador de buffer, que vai carregar as páginas para a memória principal. Além dele, temos um software na camada mais inferior que trata do gerenciamento do espaço no disco. Dessa forma, as camadas superiores alocam, liberam, lêem e escrevem páginas através das rotinas fornecidas por essa camada mais inferior, chamada de gerenciador de espaço em disco.
O SGBD suporta a concorrência e a recuperação de falha planejando cuidadosamente as solicitações do usuário e mantendo um registro de todas as alterações realizadas no banco de dados.
Os componentes do SGBD associados com o controle de concorrência e recuperação incluem o gerenciador de transações, que vai garantir que as transações peçam bloqueios e sejam desbloqueadas de acordo com um protocolo adequado de bloqueio e também vai planejar a execução das transações; o gerenciador de bloqueio, que controla as requisições por bloqueio e concede o direito de bloqueio nos objetos de banco de dados quando eles se tornam disponíveis; e o gerenciador de recuperação, que é responsável por manter um registro e restaurar o sistema a um estado consistente após a ocorrência de uma falha.
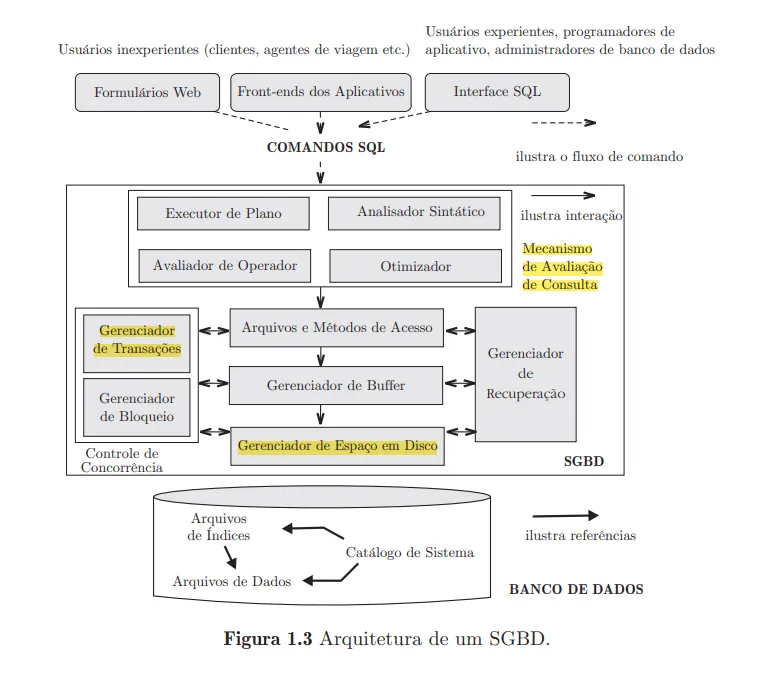
Figura representando todo o fluxo, com os três principais componentes grifados — Livro Sistemas de Gerenciamento de Banco de Dados, página 16.
3. Caracterize os diferentes SGBDs de acordo com os seus modelos de dados (principais características, vantagens e indicações de uso).
Existem alguns tipos diferentes de modelos de dados. Esses são:
- Relacional (Utilizado em inúmeros sistemas, incluindo IBM, Oracle, Sybase, etc)
- Hierárquico (SGBD IMS da IBM)
- Rede (IDS e IDMS)
- Orientado a objetos (Objectstore e Versant)
- Objeto-relacional (Infomix, Oracle, etc)
Embora vários bancos de dados utilizem os modelos hierárquico e de rede, e embora os sistemas baseados nos modelos orientado a objetos e objeto-relacional estejam ganhando aceitação no mercado, o modelo dominante atualmente é o modelo relacional. Dessa forma, inicio minha caracterização por ele:
- Relacional: Seus dados são armazenados em tabelas e sua linguagem é o SQL. Seus principais representantes são Oracle, SQL Server, MySQL e PostgreSQL. Foi o sucessor dos modelos hierárquicos e em rede. Os bancos relacionais são a opção ideal para sistemas em que é necessária uma grande consistência de dados.
- Não Relacionais: São usados em ambientes onde os bancos relacionais não atendem. Dados mistos, grandes volumes de dados e etc. São conhecidos como NoSQL (Not Only SQL) e seus principais representantes são: MongoDB, Redis e Cassandra. Buscam consistência nas informações armazenadas, disponibilidade do banco de dados e tolerância ao particionamento das informações, por isso também são utilizados em grandes soluções baseadas em nuvem.
Referências bibliográficas:
SISTEMAS de Gerenciamento de Banco de Dados. 3ª. ed. [S. l.: s. n.], 2008.
QUAIS OS PRINCIPAIS BANCOS DE DADOS E QUAIS SUAS DIFERENÇAS?. [S. l.], 26 fev. 2019. Disponível em: https://www.opservices.com.br/banco-de-dados/. Acesso em: 3 mar. 2021.